
谈谈工业企业如何将数据编织与传统数据仓库结合
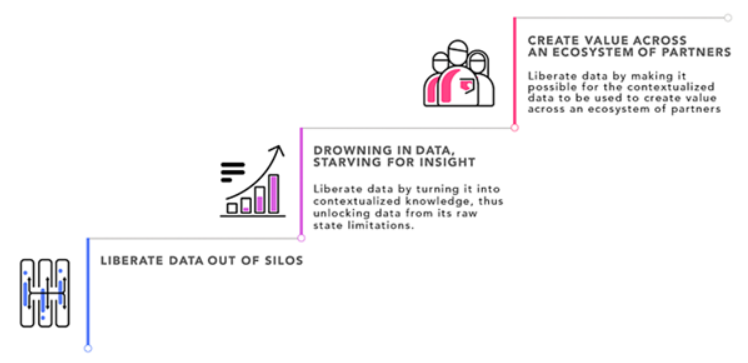
对于工业企业而言,从数据解放中获得最终价值的途径需要三个关键步骤。许多组织已经实现了第一步:从孤立的源系统中解放数据并将其聚合到传统数据仓库。第二步:从巨量的数据中挖掘价值寻找洞擦力,这要难得多。第三步:通过数据生态系统创造价值,如果成功数据价值将最大化。
在当今成熟的传统数据仓库市场中,进步的、数据驱动的组织正在积极利用 Data Fabric 解决方案作为对现有数据仓库策略的补充。通过使用 Data Fabric,组织可以再次解放他们的数据——将其从聚合池中提取出来,并将其转化为情境化知识,以实现他们对高级分析的期望。
数据编织与数据仓库的区别
Data Fabric 的两个主要支柱是数据上下文和数据发现。他们定义数据编织并使其与现有数据仓库截然不同并与之互补。
1.数据上下文是不同数据类型和数据工件内部和之间有意义的使用、案例支持关系的总和。它是在所谓的情境化管道中进行数据关系挖掘和管理的结果。向数据添加上下文的过程通常称为数据上下文化或数据融合。
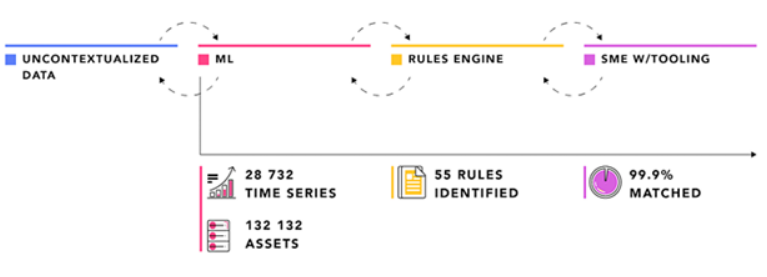
在上下文化之前,数据通常是从许多源系统集成的,并共同位于一个公共数据存储库中,类似于传统的数据仓库。或者,数据集成通过数据联合虚拟化,避免了数据复制和传输的需要。最近,混合方法变得普遍,特别是对于延迟敏感的物联网 (IoT) 数据应用程序,其中必须在数据附近执行数据聚合和数据合成。
组织应用现状
在电力和公用事业领域,数字化工作长期以来仅限于试点项目、概念验证和案例研究,没有大规模的运营项目。这主要是由于过时的 IT 基础设施依赖遗留系统,并且只为应用程序提供商启用点对点集成。这些一次性解决方案——有时包括有限的数字孪生——实际上会使数字化目标复杂化,因为由此产生的项目与原始数据一样孤立,无法扩展,成本高到浪费。
用 Data Fabric 补充现有的数据仓库解决方案大大降低了成本,同时在许多复杂的客户组织中实现了可扩展性、开发速度和数据开放性。
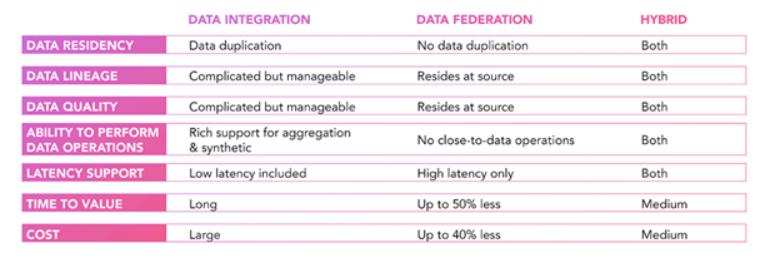
2.数据发现就是让数据以正确的格式毫不费力地提供给正确的用户。这一直是数据和信息架构师的目标。B2C 技术中的发现是即时的、自主的和不断的自我学习。换句话说,它远远领先于企业和物联网数据发现。这就是最重要的目标:从主动搜索转变为基于个性化相关性的被动发现。
最近,数据量、速度和商业价值呈指数级增长,再加上低代码和数据科学项目的迅速崛起,使得数据发现比以往任何时候都更加重要。
在企业数据管理的背景下,使正确的数据易于发现依赖于几乎相同的方法:正确的元数据、标签、与其他数据的链接以及数据编目以使其可被机器和人读取。过时的手动元数据管理正逐渐被主动的、机器学习支持的元数据实践所取代,用于从关系和集群中发现和推断新的元数据。
这就是进步组织正在寻找数据编织解决方案来补充其传统数据仓库策略的原因。Data Fabric 为现有的数据仓库的数据资产添加了关键上下文和发现。事实上,用 Data Fabric 补充传统数据仓库是推动所有三个步骤实现真正数据解放的唯一途径。
利用 Data Fabric 提高应用场景开发效率
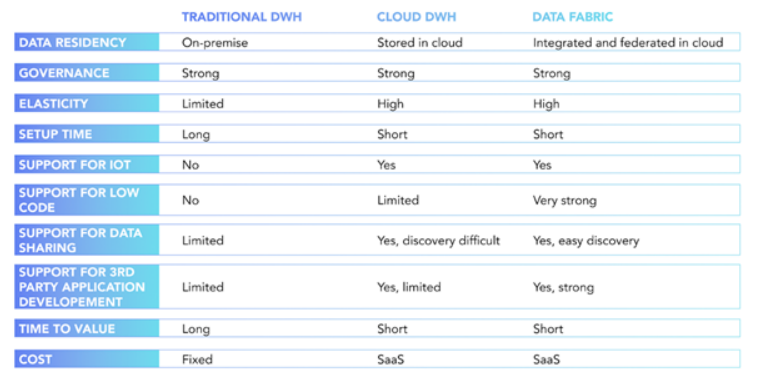
现在让我们进一步将数据编织与数据仓库放在一起。为了解决数据可访问性、可扩展性和效率带来的关键挑战,数据仓库无疑是用于业务场景交付的不断发展的技术堆栈的重要组成部分。但很明显,一些限制仍未解决。虽然数据湖为数据可重用性创造了环境,通过更好地访问其源系统中的数据以及采用支持可扩展性的标准的方式,但它未能提高开发过程的效率。
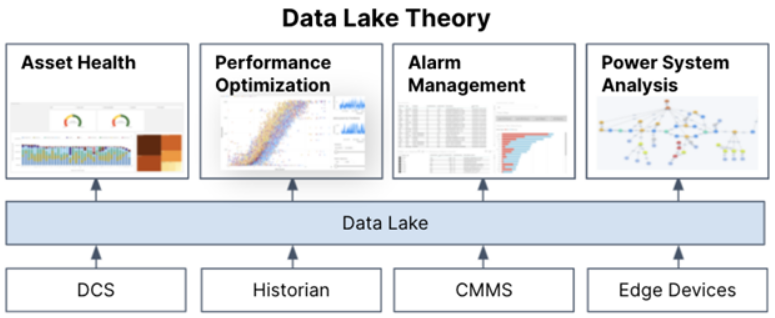
正如下图中所看到的,虽然可以在数据仓库的一个位置访问更多数据,但它仍然没有完全解决在数据对业务用例有用之前必须发生的上下文化。因此,每次在用例中使用数据时都必须将其重新上下文化,从而暴露出严重的人工效率低下问题。
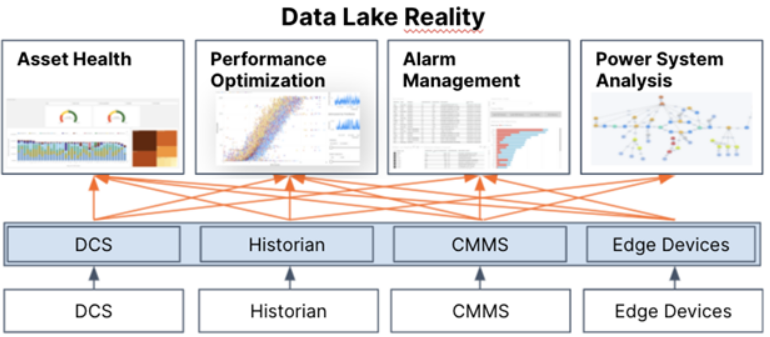
这就是 Data Fabric 作为手段发挥作用的地方:1) 使首次将数据集上下文化变得更容易,2) 自动将新数据上下文化到数据模型中,3) 使这些数据模型能够在新用例中重用。
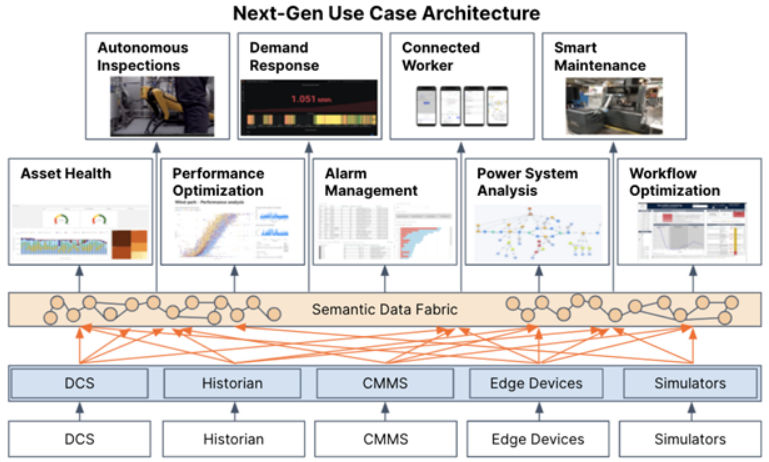
如上图所示,这种下一代架构对于避免新用例需要与第一个概念验证相同的工作量,同时减少在其生命周期中维护多个数据解决方案的 IT 负担和成本至关重要。数据解决方案堆栈在实践和架构方面不断发展,数据仓库和数据编织将继续发挥重要的共生作用。



